


Google BigQuery — это облачное корпоративное хранилище данных, которое предлагает быстрые SQL-запросы и интерактивный анализ очень больших наборов данных. BigQuery создан на основе технологии Google Dremel и предназначен для обработки данных только для чтения.
Помимо отчетов Google Analytics, BigQuery позволяет запрашивать, обрабатывать, загружать, экспортировать и визуализировать большие данные.
Платформа использует столбцовую модель хранения, которая обеспечивает гораздо более быстрый просмотр данных, а также модель древовидной архитектуры, которая делает запросы и агрегирование результатов значительно проще и эффективнее. Кроме того, BigQuery является бессерверным и обеспечивает высокую масштабируемость благодаря быстрому циклу развертывания и ценам по требованию.
Данные в BigQuery автоматически шифруются при хранении или передаче.
Архитектура хранилища данных Google BigQuery
BigQuery основан на технологии Dremel. Dremel был инструментом в Google около 10 лет.
Дремель: Он динамически выделяет сокеты для запросов по мере необходимости и распределяет их между несколькими пользователями, выполняющими запросы одновременно. Один пользователь может иметь тысячи сокетов для выполнения своих запросов. Требуется больше, чем много оборудования, чтобы ваши запросы выполнялись быстро. Запросы BigQuery основаны на механизме запросов Dremel.
Колосс: BigQuery использует Colossus, распределенную файловую систему Google последнего поколения. В каждом центре обработки данных Google есть собственный кластер Colossus, и в каждом кластере Colossus достаточно дисков, чтобы предоставить каждому пользователю BigQuery тысячи частных дисков одновременно. Colossus также занимается репликацией, восстановлением (при сбое дисков) и распределенным управлением.
Сеть Юпитера: Это внутренняя сеть центра обработки данных, которая позволяет BigQuery разделять хранение и вычисления.
Настройка Google BigQuery
Благодаря расширенным возможностям платформы по обработке данных, созданным для управления аналитикой больших петабайтных запросов, это также означает, что она может собирать больше данных из разных источников и быстрее их систематизировать.
Кроме того, объединение возможностей машинного обучения BigQuery с существующими наборами данных и структурами может улучшить структуру хранилища, упростить запросы и сканирование данных и даже снизить затраты за счет устранения избыточных структур и оптимизации хранилища для шаблонов использования отдельной организации.
BigQuery является частью Google Cloud Platform и интегрируется с другими сервисами и инструментами GCP. Большой запрос; Облачное хранилище может обрабатывать данные, хранящиеся в других продуктах GCP, включая службу реляционной базы данных Cloud SQL, базу данных Cloud Bigtable NoSQL, Google Диск и распределенную базу данных Google Spanner.
Вам не нужно беспокоиться о размере хранилища или о том, сколько оперативной памяти требуется для обработки вашего запроса или о количестве процессоров на вашем сервере. Система автоматически масштабируется для выполнения ваших запросов и выключается по завершении. Google публикует образцы баз данных, на которых вы можете попрактиковаться.
На экране настройки источника данных BigQuery всегда требуются идентификатор проекта и файл ключа JSON. Вы можете получить файл ключа при создании новой учетной записи службы в Google.
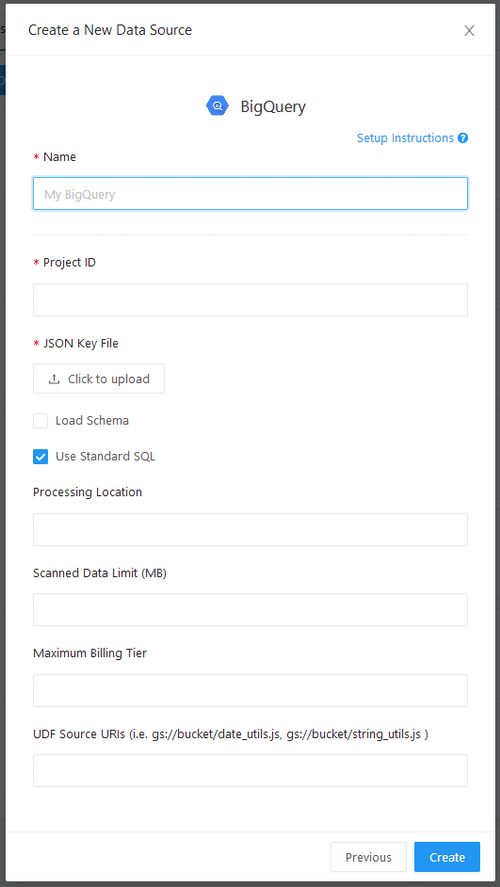
BigQuery 2.0 и более поздние версии поддерживают либо устаревший синтаксис SQL, либо стандартный синтаксис SQL. Redash поддерживает оба варианта, но по умолчанию используется стандартный SQL. Этот параметр применяется на уровне источника данных путем переключения флажка «использовать стандартный SQL». Ваш выбор здесь передается в BigQuery вместе с текстом вашего запроса. Если некоторые из ваших запросов используют устаревший SQL, а другие используют стандартный SQL, вы можете создать два источника данных.
Если вы получаете ошибку «Работа не найдена», похожую на: «Не найдено: работа». : проверьте правильность вашего местоположения рендеринга.
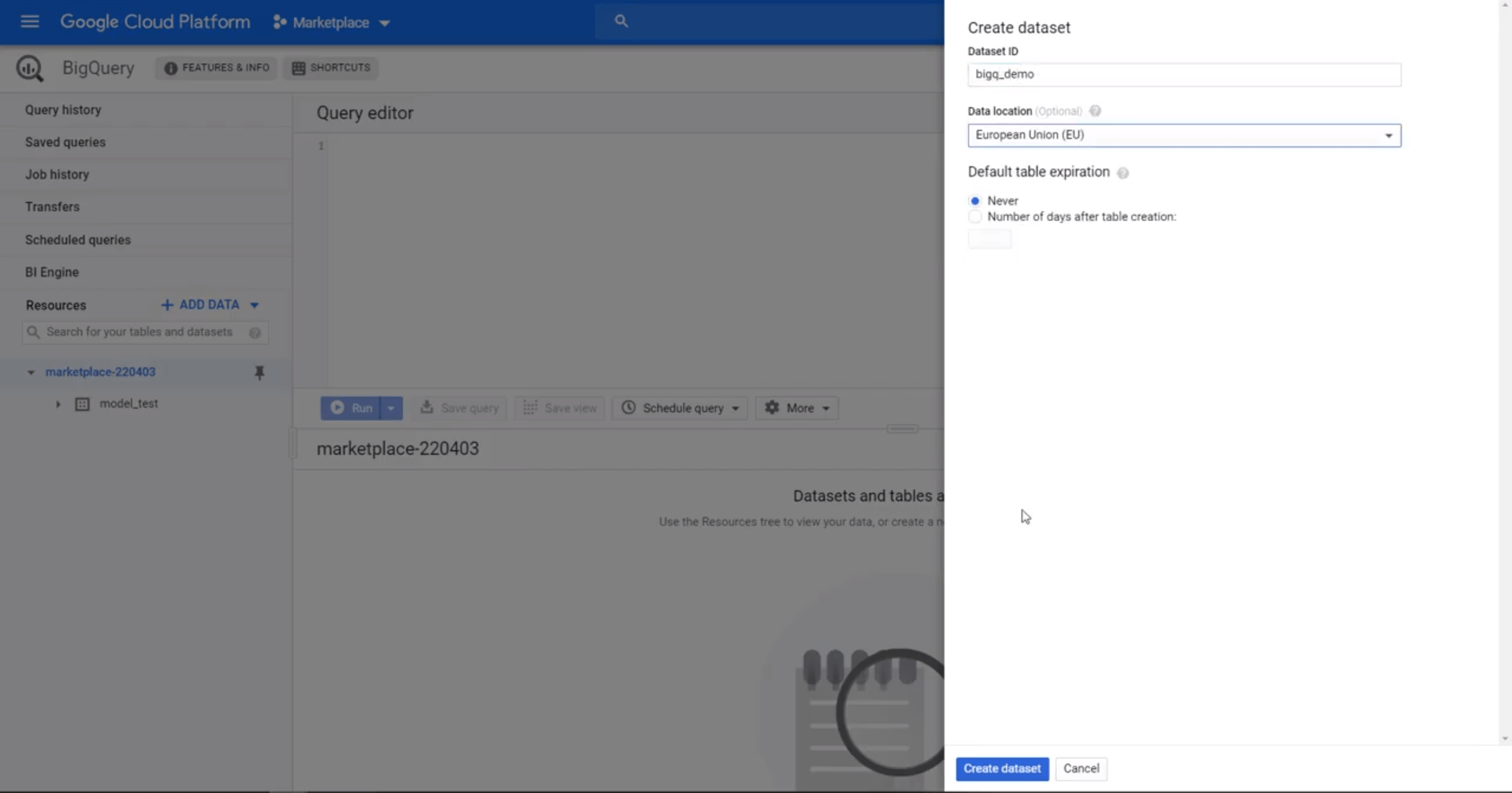
Сначала настройте Google Cloud Console и войдите в систему. Выберите или создайте проект, перейдите в BigQuery из бокового меню и создайте новый набор данных. Набор данных действует как «папка» для ваших таблиц данных, которые вы хотите загрузить.
В меню IAM и администратора создайте новую учетную запись службы с доступом к BigQuery для управления вашими данными и сгенерируйте ключ JSON для подключения BigQuery к Holistics.
Сохраните этот файл JSON на потом. Не забудьте предоставить этой учетной записи достаточные права роли BigQuery, например права администратора BigQuery.
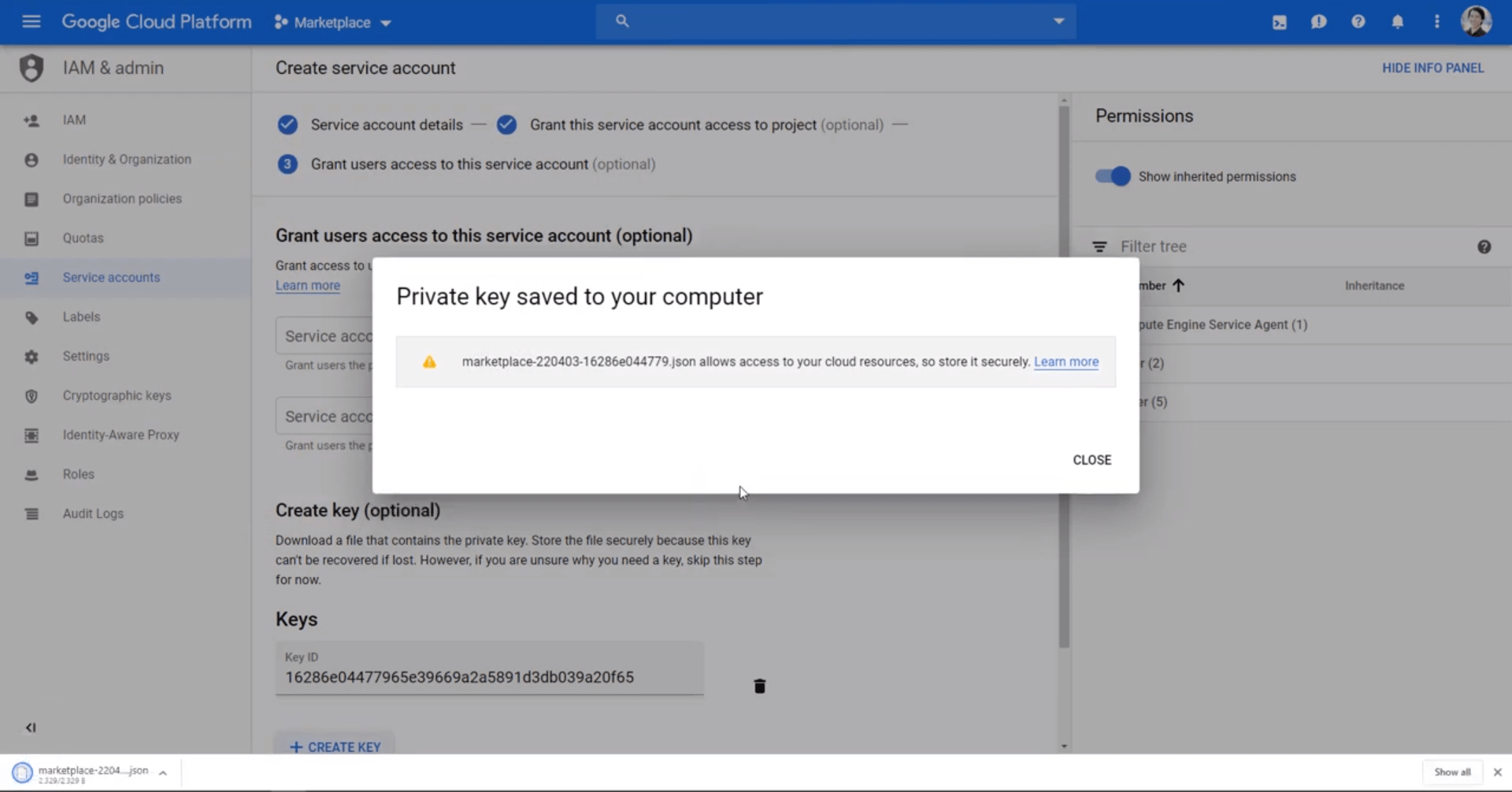
Сохраните файл JSON из нового сервисного аккаунта, чтобы позже подключить BigQuery.
Теперь, чтобы добавить новый источник данных в Holistics, выберите BigQuery в раскрывающемся меню, скопируйте значение идентификатора вашего проекта Google из консоли Google, вставьте ключ JSON, затем проверьте и сохраните источник данных BigQuery.
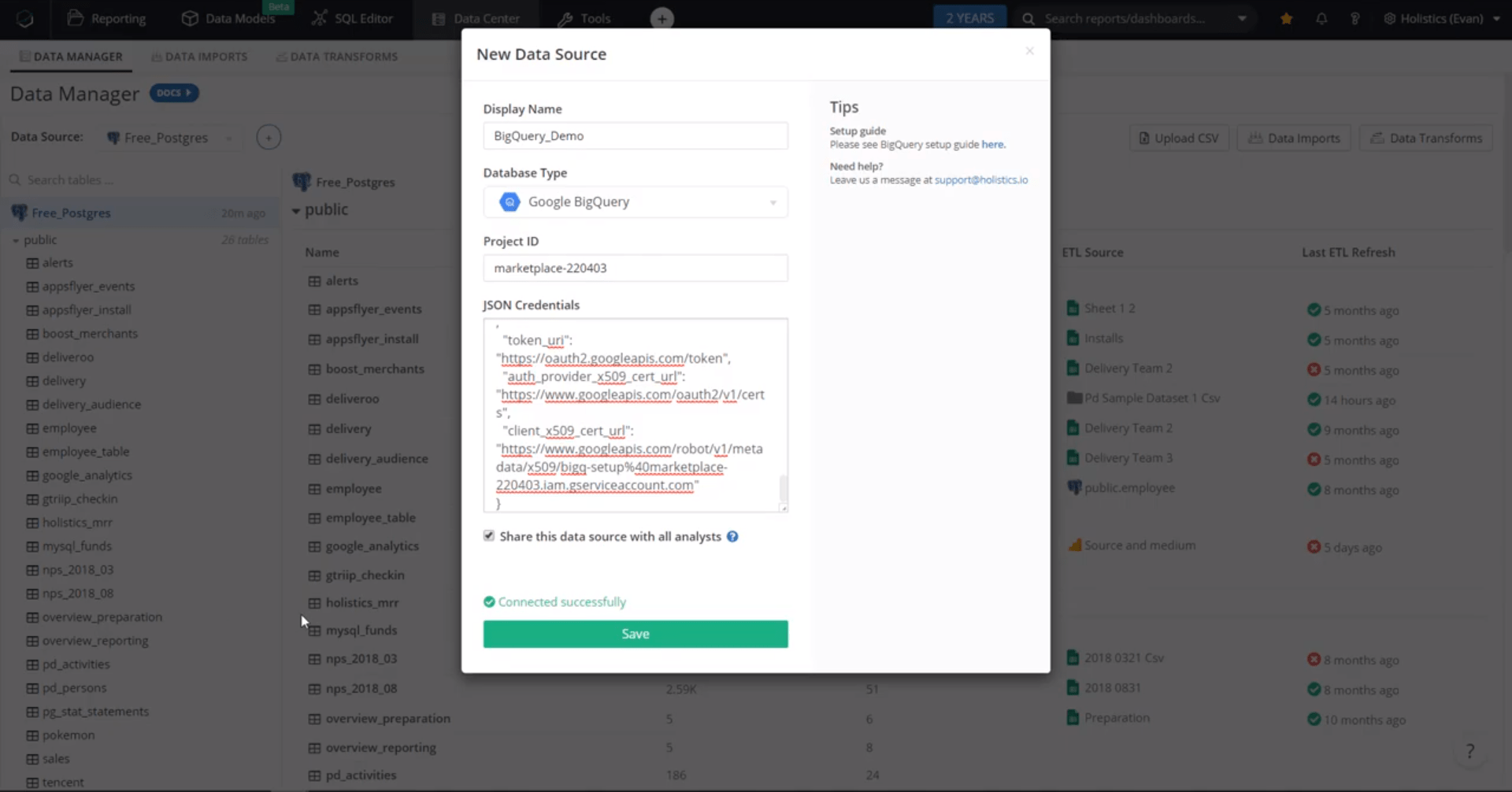
Теперь ваше хранилище данных BigQuery подключено и готово!
Теперь вы можете начать перенос данных в BigQuery для своей аналитики.

