


Google BigQuery ist ein Cloud-basiertes Data Warehouse für Unternehmen, das schnelle SQL-Abfragen und interaktive Analysen sehr großer Datensätze bietet. BigQuery basiert auf der Dremel-Technologie von Google und wurde entwickelt, um schreibgeschützte Daten zu verarbeiten.
Neben Google Analytics-Berichten ermöglicht BigQuery das Abfragen, Verarbeiten, Laden, Exportieren und Datenvisualisieren von Big Data.
Die Plattform verwendet ein spaltenförmiges Speichermodell, das ein viel schnelleres Durchsuchen von Daten ermöglicht, sowie ein Baumarchitekturmodell, das das Abfragen und Aggregieren von Ergebnissen erheblich einfacher und effizienter macht. Darüber hinaus ist BigQuery serverlos und dank seines schnellen Bereitstellungszyklus und der On-Demand-Preisgestaltung hochgradig skalierbar.
Daten in BigQuery werden im Ruhezustand oder während der Übertragung automatisch verschlüsselt.
Google BigQuery Data Warehouse-Architektur
BigQuery basiert auf der Dremel-Technologie. Dremel ist seit etwa 10 Jahren ein Tool bei Google.
Dremel: Es weist Abfragen nach Bedarf dynamisch Sockets zu und verteilt sie auf mehrere Benutzer, die gleichzeitig Abfragen durchführen. Ein einzelner Benutzer kann Tausende von Sockets haben, um seine Abfragen auszuführen. Es braucht mehr als nur eine Menge Hardware, um Ihre Abfragen schnell auszuführen. BigQuery-Anfragen werden von der Dremel-Abfrage-Engine unterstützt.
Koloss: BigQuery stützt sich auf Colossus, das verteilte Dateisystem der neuesten Generation von Google. Jedes Google-Rechenzentrum hat seinen eigenen Colossus-Cluster, und jeder Colossus-Cluster verfügt über genügend Festplatten, um jedem BigQuery-Benutzer Tausende von privaten Festplatten auf einmal zur Verfügung zu stellen. Colossus übernimmt auch Replikation, Wiederherstellung (wenn Festplatten ausfallen) und verteiltes Management.
Jupiter-Netzwerk: Es ist das interne Rechenzentrumsnetzwerk, das es BigQuery ermöglicht, Speicherung und Berechnung zu trennen.
Google BigQuery-Setup
Dank der erweiterten Datenfunktionen der Plattform – die für die Verwaltung großer Abfragen im Petabyte-Bereich entwickelt wurden – bedeutet dies auch, dass sie mehr Daten aus verschiedenen Quellen sammeln und schneller organisieren kann.
Außerdem kann die Kombination der maschinellen Lernfunktionen von BigQuery mit vorhandenen Datasets und Strukturen das Speicherdesign verbessern, Abfragen und Datenscans rationalisieren und sogar die Kosten senken, indem redundante Strukturen eliminiert und der Speicher für die Nutzungsmuster einzelner Organisationen optimiert werden.
BigQuery ist Teil der Google Cloud Platform und lässt sich in andere GCP-Dienste und -Tools integrieren. BigQuery; Cloud Storage kann Daten verarbeiten, die in anderen GCP-Produkten gespeichert sind, darunter der relationale Datenbankdienst Cloud SQL, die NoSQL-Datenbank Cloud Bigtable, Google Drive und Spanner für verteilte Datenbanken von Google.
Sie müssen sich keine Gedanken über die Größe des Speichers oder wie viel RAM benötigt wird, um Ihre Abfrage zu verarbeiten oder die Anzahl der Prozessoren auf Ihrem Server. Das System skaliert automatisch, um Ihre Abfragen auszuführen, und fährt nach Abschluss herunter. Google veröffentlicht Beispieldatenbanken, an denen Sie üben können.
Auf dem Einrichtungsbildschirm der BigQuery-Datenquelle sind immer die Projekt-ID und die JSON-Schlüsseldatei erforderlich. Sie können eine Schlüsseldatei erhalten, wenn Sie ein neues Dienstkonto bei Google erstellen.
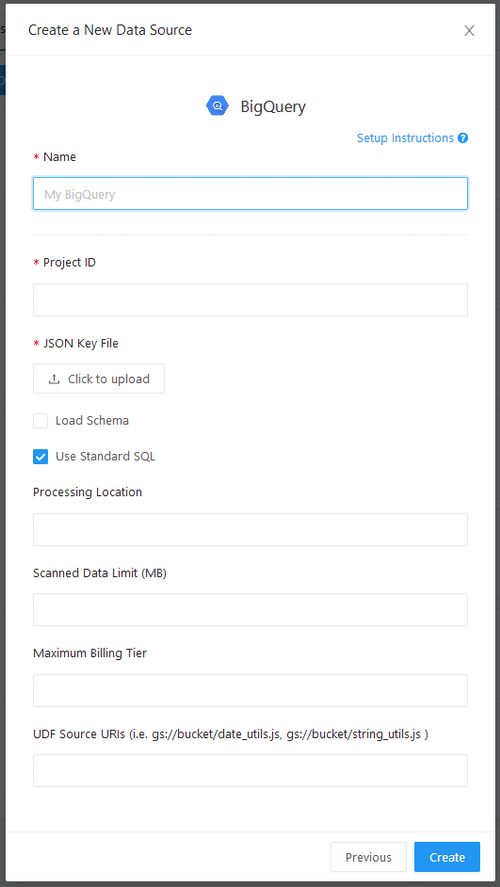
BigQuery 2.0 und höher unterstützt entweder Legacy-SQL-Syntax oder Standard-SQL-Syntax. Redash unterstützt beides, aber Standard-SQL ist der Standard. Diese Einstellung gilt auf Datenquellenebene, indem Sie das Kontrollkästchen „Standard-SQL verwenden“ umschalten. Ihre Auswahl hier wird zusammen mit Ihrem Abfragetext an BigQuery weitergegeben. Wenn einige Ihrer Abfragen Legacy-SQL und andere Standard-SQL verwenden, können Sie zwei Datenquellen erstellen.
Wenn Sie einen Job nicht gefunden-Fehler ähnlich dem folgenden erhalten: Nicht gefunden: Job : Überprüfen Sie, ob Ihr Rendering-Speicherort korrekt ist.
Richten Sie zunächst Ihre Google Cloud Console ein und melden Sie sich an. Wählen Sie ein Projekt aus oder erstellen Sie ein Projekt, gehen Sie über Ihr Seitenmenü zu BigQuery und erstellen Sie ein neues Dataset. Ein Datensatz fungiert als „Ordner“ für Ihre Datentabellen, die Sie laden möchten.
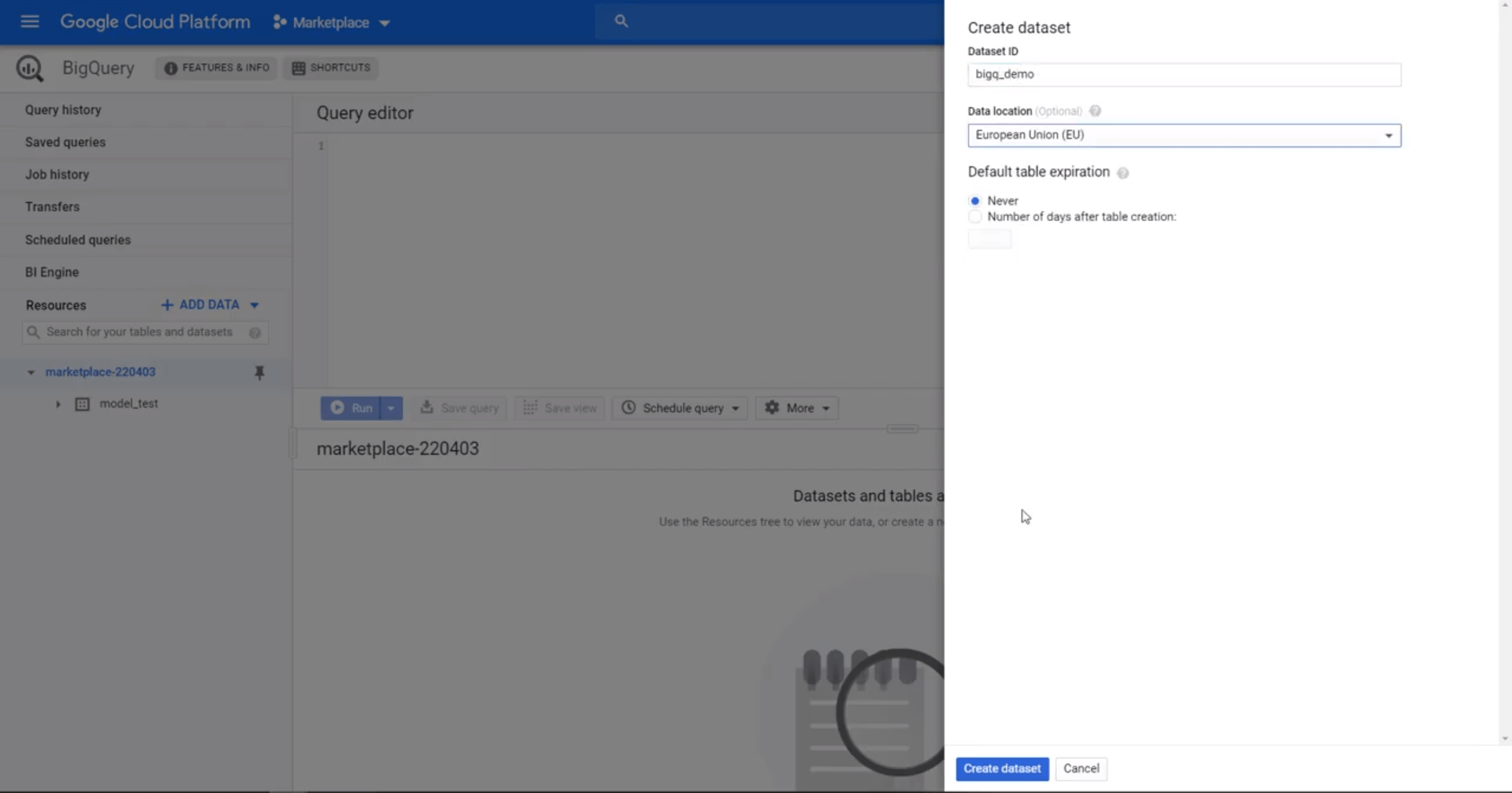
Erstellen Sie im IAM- und Admin-Menü ein neues Dienstkonto mit BigQuery-Zugriff, um Ihre Daten zu verwalten und einen JSON-Schlüssel zu generieren, um BigQuery mit Holistics zu verbinden.
Speichern Sie diese JSON-Datei für später. Denken Sie daran, diesem Konto ausreichende BigQuery-Rollenberechtigungen zu erteilen, z. B. BigQuery-Administratorberechtigungen.
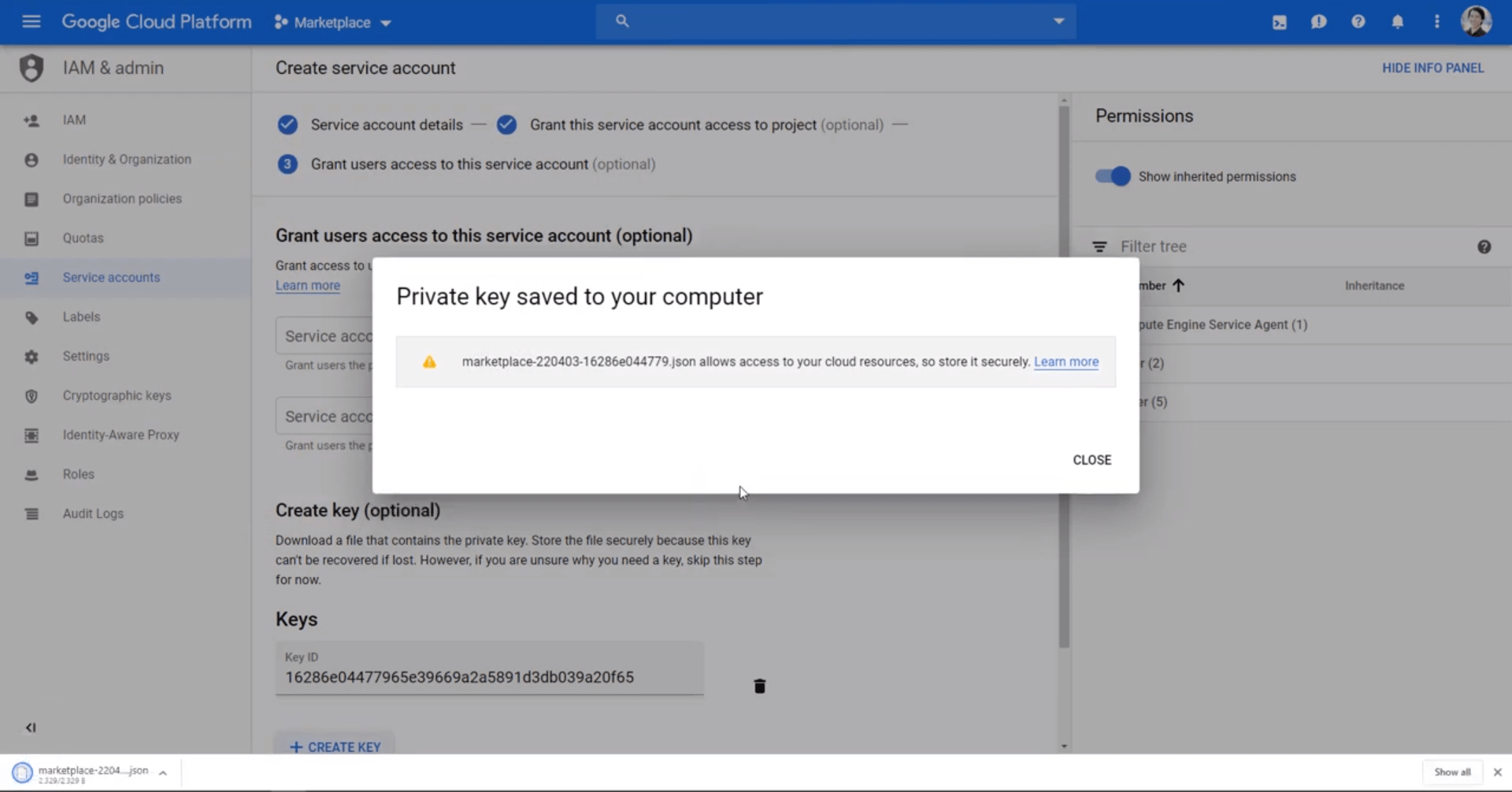
Speichern Sie Ihre JSON-Datei aus Ihrem neuen Dienstkonto, um BigQuery später zu verbinden.
Um nun eine neue Datenquelle zu Holistics hinzuzufügen, wählen Sie BigQuery aus dem Dropdown-Menü aus, kopieren Sie Ihren Google-Projekt-ID-Wert aus Ihrer Google-Konsole, fügen Sie den JSON-Schlüssel ein, testen und speichern Sie dann Ihre BigQuery-Datenquelle.
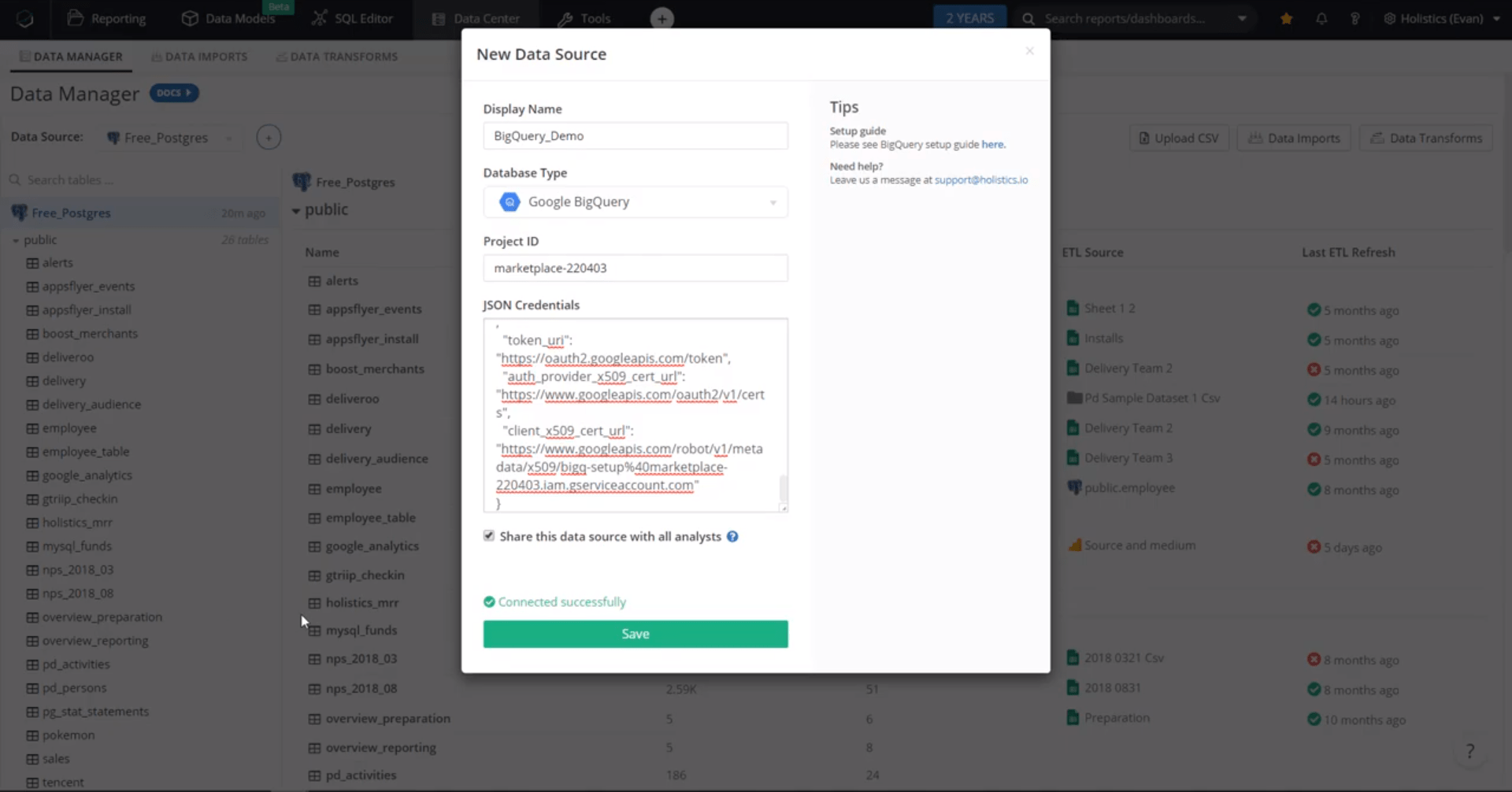
Ihr BigQuery Data Warehouse ist jetzt verbunden und bereit!
Sie können jetzt mit der Migration von Daten zu BigQuery für Ihre Analysen beginnen.

